
1. Introduction
最近怀疑项目里的多线程逻辑可能存在一些问题,导致了一些一直无法复现但是在测试中崩溃数量还挺多的问题。因为项目里的Address Sanitizer挺好用的,于是就想到了Thread Sanitizer,下称tsan。
Android其实简单做一下适配就可以跑tsan了,但是除了tsan非常非常卡之外,我们更希望能够在Windows下跑起来这类检测机制。毕竟除去像是动画并行计算这种通用的功能之外,Windows的D3D12的线程模型也挺乱的,而且项目里还做了一些异步的优化,说实话直接靠code review的方式去发现这些问题挺难的。不过tsan并不支持Windows,所以在看了各种运行时插桩方案、LLVM代码和UE5.6的代码之后,鉴于网上似乎并没有什么tsan相关的资料,就有了这篇文章。
2. Thread Sanitizer
这里先简单介绍一下tsan的原理,其实跟asan有点类似,tsan也是通过编译器插桩的方式,去检查对象地址的Shadow Memory并判断里面存的信息来达到检测data race的目的。
2.1 Data Race (数据竞争)
首先要正确理解数据竞争。在CPU侧,内存模型通过指令重排、store buffer、缓存一致性等机制影响内存访问(在CPU不同核心之间)的可见性和(甚至同一个核心下的)顺序。而在应用层面,C++标准明确规定了数据竞争属于未定义行为(Undefined Behavior),从而允许编译器不需要考虑数据竞争的情形就可以激进地对代码进行优化,下面举几个例子。
2.1.1 指令重排
2.1.1.1 编译器侧
这里thread0中两次赋值就是可以被编译器重排以优化CPU流水线效率的,这里编译器的重排是由C++标准指导的,跟CPU架构无关。
int32_t GVal;
bool GFlag;
void thread0() {
GVal = 114514;
// 需要内存屏障以保证顺序
GFlag = true;
}
void thread1() {
if (GFlag) {
GVal++;
}
}2.1.1.2 CPU侧
这是Intel Core 2架构图,可以对照着看。里面的Reservation Station就是指令调度器,只要端口有空闲就会无序地发射里面可以被执行的指令。
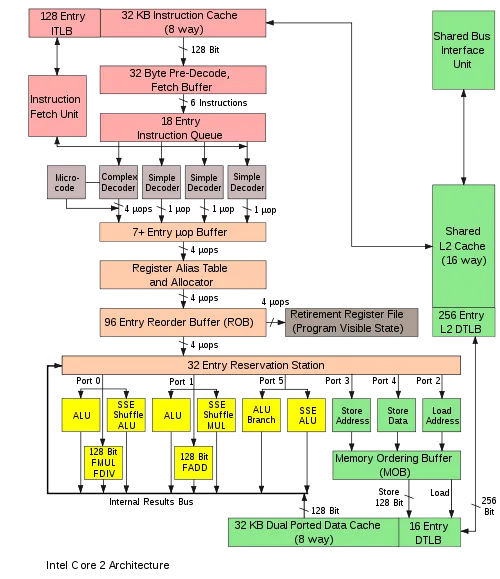
注意,数据竞争问题应该没有在CPU侧定义,下面提到的机制只是会暴露或放大应用层面的数据竞争问题。数据竞争是代码写的有问题,而不是CPU的问题(逃。
乱序执行:x86_64下(ARM不太清楚),CPU的指令重排通常发生在CPU的指令调度器中,此时指令通过了解码器前端(将原始可变长opcode通过微码ROM保存的信息解码为真正要被执行的指令)和后端的寄存器分配、重命名阶段。指令调度器中同时会有多个指令,前置依赖已完成或没有依赖的指令会被视为可发射到后续流水线的,指令的发射就可能是乱序的,而且此时CPU也并不能知道其它核心(也就是其它线程)的数据依赖。StoreBuffer导致的部分问题其实也跟乱序执行有关,这里不展开讲了。
x86_64保证了较强的内存序,只会发生Store-Load重排且保证被重排的两条指令的操作地址不同。而ARM就难说了,如图:
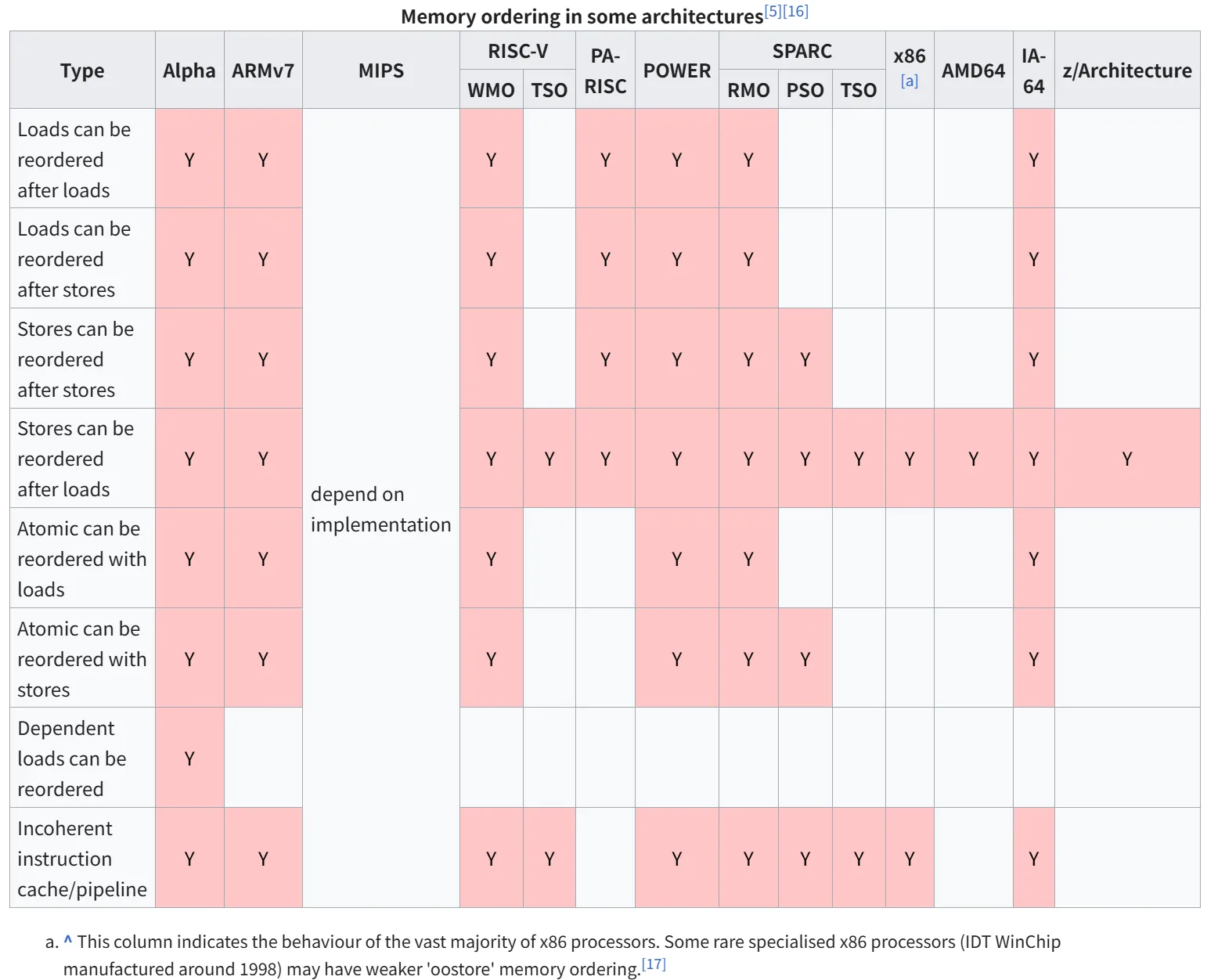
缓存一致性:为了保证核间缓存(L1缓存通常不是核间共享的)一致性,引入了MESI协议。这就有一个问题——如果直接在原来的执行单元实现这个协议不就等于给每个核之间加了一个锁?所以又引入了一个Store Buffer用于缓存要被提交的Store操作,在执行了所有Invalidation Ack之后,再去执行这些被缓存的Store操作。
但是这中间当前核心还是要继续发射有数据依赖的指令啊,前面的指令要是一直卡在Store Buffer的话,岂不是会把整个流水线卡住?所以又双叒叕引入了一个Store Forwarding的概念,允许当前核心在读取某个数据时先从Store Buffer里取值。这也引入了一个问题,就是在Store Buffer没有被刷新之前这段时间执行的指令,即使其它核心发送了Invalidate消息,当前核心读到的值依旧可能是旧值。更别说虽然Invalidation Ack是立即被发送的,但是Invalidate操作本身也有一个Invalidation Buffer,读/写屏障就是分别告诉处理器要先完成所有Store Buffer/Invalidation Buffer中的消息才能够执行下一条指令。
2.1.2 表达式没有原子性
除此之外,C++中某些看起来很简单的表达式也并非是一条指令就可以完成的,如
uint32_t i = 0;
// ...
i++;在x86_64下关闭优化时会生成这样的汇编代码,更别提ARM了:
mov eax, dword ptr [rip + i]
add eax, 1
mov dword ptr [rip + i], eax当然优化级别高的情况下可以优化成inc指令,但是语言标准并不支持编写者直接做这个假设。
2.2 要怎么检查呢
整个tsan分为了两块,这里简单讲讲,有兴趣的可以拉一个LLVM下来看看,我这里用的是llvmorg-21.1.5 tag拉的。
2.2.1 编译期
其一是编译期的插桩Pass,位于llvm\lib\Transforms\Instrumentation\ThreadSanitizer.cpp,实现得挺简单的,逻辑如下:
- 插入tsan初始化函数到模块的静态初始化函数列表中 (
void insertModuleCtor); - 遍历所有函数 (
bool ThreadSanitizer::sanitizeFunction); - 遍历函数中的指令,找到属于Load-Store/Atomic-Op/MemInstrinCall的指令,其中MemInstrin指的是类似
memset之类的,用于避免memset被内联从而漏掉插桩; - 如果上述指令未被捕获,或处于同一BasicBlock(控制流分析的基本单元,同一BasicBlock中控制流是线性的)中且读写之间没有其它函数调用,则跳过该指令。否则针对指令的类型执行插桩,插桩的函数具体实现由运行时库提供。 (
void ThreadSanitizer::chooseInstructionsToInstrument)。
内存访问操作插桩的运行时函数如下,详细参见bool ThreadSanitizer::instrumentLoadOrStore:
__tsan_read{1,2,4,8,16}/__tsan_write{1,2,4,8,16}__tsan_unaligned_read{...}/__tsan_unaligned_write{...}__tsan_volatile_read{...}/__tsan_volatile_write{...}__tsan_read_write{1,2,4,8,16}
原子操作插桩参见bool ThreadSanitizer::instrumentAtomic;
Instrinsic插桩参见bool ThreadSanitizer::instrumentMemIntrinsic。
2.2.2 运行时
其二则是运行时,位于compiler-rt\lib\tsan,作用是提供插桩函数的实现、tsan线程状态上下文以及对Synchronization Primitive(同步原语)的hook操作。我们将这些功能拆开讲。
2.2.2.1 Shadow Memory
与asan类似,tsan也利用了Shadow Memory来给每个对象指针映射了一块用于保存tsan数据的虚拟内存区域,以便加速用户空间指针到tsan数据的访问。大概映射机制如下:
Shadow Addr = Obj Ptr >> 3 + kShadowBeg
Object Addr = (Shadow Ptr - kShadowBeg) << 3是一个非常简单的线性映射,kShadowBeg是一个常量,不同平台不一样。每8字节应用内存对应32字节(4个8字节)shadow数据。
Shadow数据结构如下:
// tsan_shadow.h
// 省略了函数
class Shadow {
struct Parts {
u8 access_; // 访问位掩码,分别对应八字节
Sid sid_; // 线程槽ID
u16 epoch_ : kEpochBits; // 时间戳,是运行时线程内部的时间戳,与执行的同步操作有关,在线程内部是单调递增的
u16 is_read_ : 1; // 读操作标志
u16 is_atomic_ : 1; // 原子操作标志
};
union {
Parts part_;
u32 raw_;
};
};线程状态结构中保存了FastState,用于快速构造一个Shadow,结构如下:
// tsan_shadow.h
class FastState {
struct Parts {
u32 unused0_ : 8; // Padding, 预留
u32 sid_ : 8; // 线程槽ID
u32 epoch_ : kEpochBits; // 线程当前时间戳
u32 unused1_ : 1;
u32 ignore_accesses_ : 1; // 忽略标志
};
union {
Parts part_;
u32 raw_;
};
};访问某块内存时,通过插桩的函数,tsan运行时会从线程的FastState读取信息并写入对应的Shadow Memory。
2.2.2.2 Vector Clock
tsan使用Vector Clock算法来追踪线程间的happens-before关系。每个线程和同步对象都维护一个Vector clock:
// tsan_vector_clock.h
class VectorClock {
Epoch clk_[kThreadSlotCount]; // 固定大小数组,每个线程一个epoch
public:
Epoch Get(Sid sid) const { return clk_[sid]; }
void Set(Sid sid, Epoch v) { clk_[sid] = v; }
void Acquire(const VectorClock* src); // C = max(C, src)
void Release(VectorClock** dstp) const; // *dst = max(*dst, C)
void ReleaseStore(VectorClock** dstp) const; // *dst = C
};具体用法可以看compiler-rt\lib\tsan\rtl\tsan_rtl_thread.cpp和compiler-rt\lib\tsan\rtl\tsan_rtl_mutex.cpp,这里不多赘述(怕说错。
那么现在要如何确定有没有happens-before关系呢?给定两个访问:
- 访问1:线程A在时间戳(epoch) E1 时访问
- 访问2:线程B在时间戳(epoch) E2 时访问
其中访问1是已经发生了的,访问信息被记录在Shadow Memory中。当访问2发生时,我们检查被访问内存记录在Shadow Memory中的线程的时间戳Eold,如果大于E1的话(clock[A] >= E1),则表示线程B已经同步了线程A在E1时的所有操作,保证这两次访问存在happens-before关系,也就是说这两次访问没有产生Data Race。
具体代码:
// tsan_rtl_access.cpp
ALWAYS_INLINE
bool CheckRaces(ThreadState* thr, RawShadow* shadow_mem, Shadow cur,
int unused0, int unused1, AccessType typ) {
bool stored = false;
for (uptr idx = 0; idx < kShadowCnt; idx++) {
RawShadow* sp = &shadow_mem[idx];
// 省略其它跳过条件,感兴趣可以去看源码了解一下
if (LIKELY(thr->clock.Get(old.sid()) >= old.epoch()))
continue;
// 省略
}
// 省略
}2.2.2.3 Thread State与Epoch
线程状态结构体如下,里面保存了检查所需的状态,每个线程一个:
// tsan_rtl.h
// 省略了很多无关紧要的字段
struct alignas(SANITIZER_CACHE_LINE_SIZE) ThreadState {
FastState fast_state; // 当前sid和epoch
VectorClock clock; // 本线程的vector clock
Tid tid; // 线程唯一ID
TidSlot *slot; // 线程槽(可复用)
Processor *proc; // 处理器(资源缓存)
};而Epoch会在release操作后递增:
// tsan_rtl_mutex.cpp
void IncrementEpoch(ThreadState *thr) {
DCHECK(!thr->ignore_sync);
DCHECK(thr->slot_locked);
Epoch epoch = EpochInc(thr->fast_state.epoch());
if (!EpochOverflow(epoch)) {
Sid sid = thr->fast_state.sid();
thr->clock.Set(sid, epoch);
thr->fast_state.SetEpoch(epoch);
thr->slot->SetEpoch(epoch);
TraceTime(thr);
}
}这里Release操作就是std::memory_order_release这个release,也就是跟其它核心说赶紧刷新你的Invalidation Buffer再继续执行命令,我写完了。到这里也就完成了一次写入和核间同步,所以Epoch递增1。
2.2.3 同步点
篇幅可能太长了,我也懒得写。这里直接让Claude 4.5 sonnet生成了分析,我放到文章末尾以供参考。
2.2.4 数据竞争检测
当发生内存访问时,通过插桩函数会执行到这里:
// tsan_rtl_access.cpp
ALWAYS_INLINE void MemoryAccess(ThreadState* thr, uptr pc, uptr addr,
uptr size, AccessType typ) {
RawShadow* shadow_mem = MemToShadow(addr);
FastState fast_state = thr->fast_state;
Shadow cur(fast_state, addr, size, typ);
// 检查是否包含相同访问,快速跳过
if (LIKELY(ContainsSameAccess(shadow_mem, cur, shadow, access, typ)))
return;
if (UNLIKELY(fast_state.GetIgnoreBit()))
return;
// 记录访问到trace
if (!TryTraceMemoryAccess(thr, pc, addr, size, typ))
return TraceRestartMemoryAccess(thr, pc, addr, size, typ);
// 检查竞争
CheckRaces(thr, shadow_mem, cur, shadow, access, typ);
}所以这个检测在Android上开起来就会卡得基本啥也干不了……下面会提到如何处理这个问题。我们接着看上面提到过的CheckRaces函数:
bool CheckRaces(ThreadState* thr, RawShadow* shadow_mem, Shadow cur,
m128 shadow, m128 access, AccessType typ) {
// 1. 检查访问是否相交(access位掩码),比如一个线程访问低字节另一个线程访问高字节是安全的
const m128 access_and = _mm_and_si128(access, shadow);
const m128 intersect = _mm_and_si128(access_and, mask_access);
// 2. 检查是否同一线程,是的话就写入Shadow然后跳过
const m128 not_same_sid = _mm_and_si128(access_xor, mask_sid);
const m128 same_sid = _mm_cmpeq_epi32(not_same_sid, zero);
// 3. 检查是否都是读或都是原子,Read-Read或者都是原子操作也是安全的
const m128 both_read_or_atomic = _mm_and_si128(access_and, mask_read_atomic);
// 4. 综合判断:相交 && 不同线程 && !(都是读或原子)
const m128 no_race = _mm_or_si128(
_mm_or_si128(not_intersect, same_sid), both_read_or_atomic);
const int race_mask = _mm_movemask_epi8(_mm_cmpeq_epi32(no_race, zero));
if (UNLIKELY(race_mask)) {
// 5. 加载线程的vector clock,检查happens-before
for each candidate in race_mask {
u8 sid = shadow[idx].sid;
u16 my_epoch = thr->clock.Get(sid);
u16 shadow_epoch = shadow[idx].epoch;
if (my_epoch < shadow_epoch) {
// 没有happens-before,说明发现了一个数据竞争问题
DoReportRace(thr, shadow_mem, cur, prev, typ);
return true;
}
}
}
// 6. 无竞争,更新shadow
StoreShadow(&shadow_mem[index], cur.raw());
return false;
}竞争条件(同时满足):
- 地址相交:访问的字节范围重叠
- 不同线程:sid不同
- 至少有一个写:不是都读且不是都原子
- 无happens-before:
thr->clock.Get(old.sid) < old.epoch
至于报告的生成就不用多说了,编译期可以在每个函数调用和返回处进行插桩,高效记录当前调用栈。不在乎这点卡顿也可以直接栈回溯。
3 Race Detector
在试完那些卡的要死还会崩溃的运行时插桩方案之后,我在逛UDN的时候(这个帖子),发现UE5.6悄咪咪地加上了一个RaceDetector功能。扫了下源码发现其实就是精简版的tsan,机制几乎一致,就连插桩Pass也有很大一部分是源自tsan的插桩Pass,所以我这里就不多赘述相关原理了。
作者很巧妙地规避了卡到爆炸的问题——加个全局开关+运行时Patch函数,启动时只运行基本的调用栈收集,在打开开关后使用detours库动态patch函数的opcode,让原本的空函数跳转到运行时库的检查函数中,就可以开始检查数据竞争。再给这个开关加个超时机制(我抄的时候作者正好给它改坏了哈哈哈),就可以在到时间时候关闭检查功能,恢复正常运行。这样我们就可以把这个工具接入到自动化检测流程中了。
在我写这篇文章的时候,这个工具已经成功地在***(项目代号)的UE4.26中跑起来了,并且能正常检查数据竞争问题。因为每个项目可能出现的问题不同,这里说一下一些移植的关键点。
3.1 编译器
检测需要依赖Clang的插桩Pass,所以UE4和魔改过的UE要修复一下引擎和项目在Clang下的编译,一般都是一些宏、模板的小错误。编辑器的问题可能多点,可以先不处理编辑器的问题。UE4.26使用Clang编译会有些静态初始化顺序的问题,可以改成将静态变量放在函数体中的形式的建议直接这样改。对于改起来很麻烦的(比如那坨Shader注册宏)可以使用__attribute__((init_priority(101)))来指定静态初始化顺序,0到100是编译器保留值,值越小则该变量的构造函数越先被执行。
UE5.6提供了已经编译好的的编译器,在执行完Setup.bat后位于Engine/Binaries/Win64/UnrealInstrumentation,可以直接使用,编译器使用的插桩函数列表如下,被插桩的模块在链接时需要可以找到这些函数的实现。
extern "C" {
void AnnotateHappensBefore(const char* f, int l, void* addr);
void AnnotateHappensAfter(const char* f, int l, void* addr);
void __Instrument_FuncEntry(void* ReturnAddress);
void __Instrument_FuncExit();
void __Instrument_StoreRange(uint64 Address, uint32 Size);
void __Instrument_LoadRange(uint64 Address, uint32 Size);
void __Instrument_Store(uint64 Address, uint32 Size);
void __Instrument_Load(uint64 Address, uint32 Size);
void __Instrument_VPtr_Store(void** Address, void* Value);
void __Instrument_VPtr_Load(void** Address);
}如果某些模块很安全,不需要被插桩,可以自行编译clang,增加-finstr-include-modules、-finstr-exclude-modules、-finstr-exclude-functions=等参数,然后传递到CustomMemoryInstrumentationPass的构造函数里面,相关排除逻辑作者原本就已经写好。关键文件是clang\include\clang\Driver\Options.td、clang\include\clang\Basic\CodeGenOptions.h。与此同时,也可以根据项目需要增加一些跳过插桩的逻辑以提高性能。
可以参考tsan移植一些逻辑。链接器可以直接使用ld.lld,亲测没啥问题,而且可以无缝切换,LLVM的链接器是部分兼容MSVC的参数的。
在接入编译器的时候,可以不用PerModuleInline.inl,直接把__Thunk开头的函数删掉__Thunk前缀即可。如果还是希望接的话,UE5很方便,UE4需要加个判断:只在模块是LaunchModule或者模块的LinkType是Modular的时候将这个文件加入编译即可。不建议在创建UnityBuild文件的时候加入,虽然也没啥问题,但是要改两个地方,可以直接改要编译的Cpp文件列表。
使用/imsvc参数添加Clang的include path。因为MSVC直接使用编译器处理Intrinsic函数;而Clang是在头文件中提供了Intrinsic函数的实现,后续在优化Pass中替换为当前架构下可以使用的指令。如果不加的话有些使用了intrinsic的库会编不过。
3.2 运行时
性能
启用后会特别卡,没有专门测。13900K大概一秒多一帧的样子,将运行时函数的数据写入向量化对这个性能看起来并没有什么帮助。自动化跑的时候建议是隔一会开一下。
与tsan对应的概念
SyncObject=>SyncVarFClock=>EpochFContext=>ThreadState
一些值得注意的地方
运行时没什么特别大的坑,根据自己的需求抄就行,可以先把插桩的函数实现接了,空函数也无所谓,测一下能不能编过。因为插桩提供的FuncEntry和FuncExit调用可以非常低成本地获取当前调用栈,而且可以包含内联函数,所以也可以利用这个插桩包搞一个类似LLM Tracker的工具。
要注意容器和函数的使用,运行时库提供的插桩实现中不能调用会被插桩的函数,否则会造成递归爆栈。
Windows下的同步原语可以通过MSVC STL中的mutex实现挖出来,断个点就行。怀疑是误报的话建议在疑似有做同步的地方断点跟进去,底层的ResumeThread、WaitForSingleObject、SetEvent、WaitOnAddress、EnterCriticalSection等函数应该会被hook,如果发现没有,那就是漏了,加上就好。另外一定要hook这几个函数:RtlFreeHeap、RtlReAllocateHeap、RtlAllocateHeap,因为即使重载了new/delete,还是有很多地方会直接使用系统的内存分配的。
初始化逻辑直接在WinMain开头调用就行,如果只在游戏包跑的话DllMain可以不要。
使用UE5.6自带的那个Clang 18魔改的编译器似乎会有部分内联函数重复插入FuncEntry的情况,所以我升级到了Clang 21。没有深究,感觉像是逃逸分析有点问题。
4. 附录
同步点
SyncVar结构
同步对象的元数据:
// tsan_sync.h
struct SyncVar {
uptr addr; // 同步对象地址
Mutex mtx; // 保护自身的互斥锁
StackID creation_stack_id; // 创建栈
Tid owner_tid; // 当前持有者线程ID
FastState last_lock; // 最后加锁的FastState
int recursion; // 递归计数
atomic_uint32_t flags; // 标志位
VectorClock *read_clock; // 读锁的vector clock
VectorClock *clock; // 写锁的vector clock
};同步原语
- pthread_rwlock:维护
read_clock和clock两个vector clock - pthread_cond_wait:
- wait前:
Release(&cond->clock)+ unlock mutex - wait后:lock mutex +
Acquire(cond->clock)
- wait前:
- pthread_barrier_wait:所有线程release,然后所有线程acquire
- sem_post/sem_wait:release/acquire语义
- pthread_join:子线程结束时release,join时acquire
原子操作
TSan将原子操作替换为运行时调用:
// tsan_interface_atomic.cpp
template <typename T>
T __tsan_atomic_load(const volatile T *a, morder mo) {
ThreadState *thr = cur_thread();
// 快速路径:relaxed不需要同步
if (mo != mo_acquire && mo != mo_seq_cst) {
MemoryAccess(thr, pc, (uptr)a, sizeof(T), kAccessRead | kAccessAtomic);
return atomic_load(to_atomic(a), to_mo(mo));
}
// Acquire语义:从同步对象获取clock
T v = atomic_load(to_atomic(a), to_mo(mo));
SyncVar *s = ctx->metamap.GetSyncIfExists((uptr)a);
if (s) {
SlotLocker locker(thr);
ReadLock lock(&s->mtx);
thr->clock.Acquire(s->clock);
v = atomic_load(to_atomic(a), to_mo(mo)); // 重新读取保证一致性
}
MemoryAccess(thr, pc, (uptr)a, sizeof(T), kAccessRead | kAccessAtomic);
return v;
}
template <typename T>
void __tsan_atomic_store(volatile T *a, T v, morder mo) {
ThreadState *thr = cur_thread();
MemoryAccess(thr, pc, (uptr)a, sizeof(T), kAccessWrite | kAccessAtomic);
if (mo == mo_relaxed) {
atomic_store(to_atomic(a), v, to_mo(mo));
return;
}
// Release语义:将clock写入同步对象
SlotLocker locker(thr);
auto s = ctx->metamap.GetSyncOrCreate(thr, pc, (uptr)a, false);
{
RWLock lock(&s->mtx, true);
thr->clock.Release(&s->clock);
atomic_store(to_atomic(a), v, to_mo(mo));
}
IncrementEpoch(thr);
}RMW原子操作
template <typename T, T (*F)(volatile T *v, T op)>
static T AtomicRMW(ThreadState *thr, uptr pc, volatile T *a, T v, morder mo) {
MemoryAccess(thr, pc, (uptr)a, sizeof(T), kAccessWrite | kAccessAtomic);
if (mo == mo_relaxed)
return F(a, v); // 快速路径
SlotLocker locker(thr);
auto s = ctx->metamap.GetSyncOrCreate(thr, pc, (uptr)a, false);
{
RWLock lock(&s->mtx, true);
// AcqRel语义:先Acquire再Release
if (IsAcqRelOrder(mo))
thr->clock.ReleaseAcquire(&s->clock);
else if (IsReleaseOrder(mo))
thr->clock.Release(&s->clock);
else if (IsAcquireOrder(mo))
thr->clock.Acquire(s->clock);
v = F(a, v); // 执行RMW操作
}
if (IsReleaseOrder(mo))
IncrementEpoch(thr);
return v;
}内存屏障
void __tsan_atomic_thread_fence(morder mo) {
ThreadState *thr = cur_thread();
if (mo == mo_acquire || mo == mo_acq_rel || mo == mo_seq_cst) {
// Acquire fence:从全局状态acquire
AcquireGlobal(thr);
}
if (mo == mo_release || mo == mo_acq_rel || mo == mo_seq_cst) {
// Release fence:release到全局状态
ReleaseGlobal(thr);
IncrementEpoch(thr);
}
__sync_synchronize(); // 硬件屏障
}
void AcquireGlobal(ThreadState *thr) {
// 从所有其他线程的当前状态acquire
for (int i = 0; i < kThreadSlotCount; i++) {
Epoch epoch = ctx->slots[i].epoch();
thr->clock.Set(i, max(thr->clock.Get(i), epoch));
}
}Memory Order映射
TSan将C++11的memory order映射到vector clock操作:
| Memory Order | TSan操作 | 说明 |
|---|---|---|
relaxed | 仅标记为atomic | 无同步,但不与非原子操作竞争 |
acquire | Acquire(sync->clock) | 获取同步对象的happens-before |
release | Release(&sync->clock) | 建立happens-before给后续acquire |
acq_rel | ReleaseAcquire | 先release再acquire |
seq_cst | 同acq_rel + 全局顺序 | 最强的顺序保证 |